R1一周年,DeepSeek Model 1悄然现身
R1一周年,DeepSeek Model 1悄然现身2025 年 1 月 20 日,DeepSeek(深度求索)正式发布了 DeepSeek-R1 模型,并由此开启了新的开源 LLM 时代。在 Hugging Face 刚刚发布的《「DeepSeek 时刻」一周年记》博客中,DeepSeek-R1 也是该平台上获赞最多的模型。
来自主题: AI资讯
11249 点击 2026-01-21 09:51
 搜索
搜索
2025 年 1 月 20 日,DeepSeek(深度求索)正式发布了 DeepSeek-R1 模型,并由此开启了新的开源 LLM 时代。在 Hugging Face 刚刚发布的《「DeepSeek 时刻」一周年记》博客中,DeepSeek-R1 也是该平台上获赞最多的模型。

GRPO 是促使 DeepSeek-R1 成功的基础技术之一。最近一两年,GRPO 及其变体因其高效性和简洁性,已成为业内广泛采用的强化学习算法。
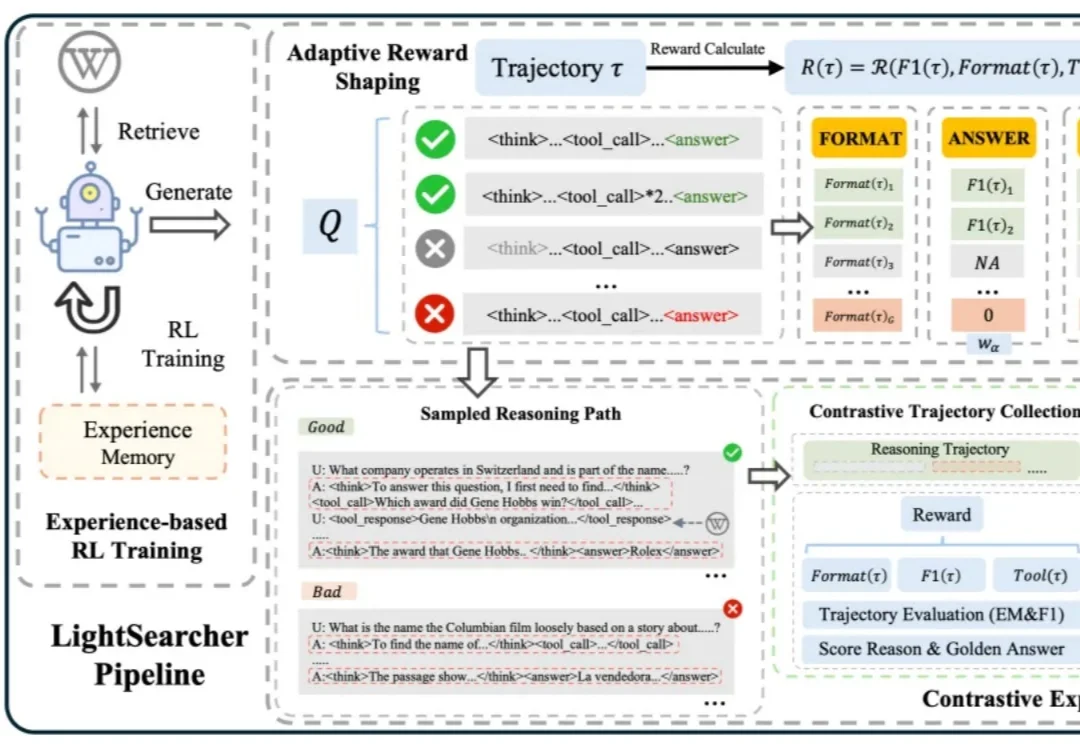
如今,以 DeepSeek-R1 为代表的深度思考大模型能够处理复杂的推理任务,而DeepSearch 作为深度思考大模型的核心搜索器,在推理过程中通过迭代调用外部搜索工具,访问参数边界之外的最新、领域特定知识,从而提升推理的深度和事实可靠性。

开源模型再次迎来一位重磅选手,就在刚刚,小米正式发布并开源新模型 MiMo-V2-Flash。

12 月 1 日,DeepSeek 一口气发布了两款新模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。几天过去,热度依旧不减,解读其技术报告的博客也正在不断涌现。知名 AI 研究者和博主 Sebastian Raschka 发布这篇深度博客尤其值得一读,其详细梳理了 DeepSeek V3 到 V3.2 的进化历程。
就在前天,DeepSeek 一口气上新了两个新模型,DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。
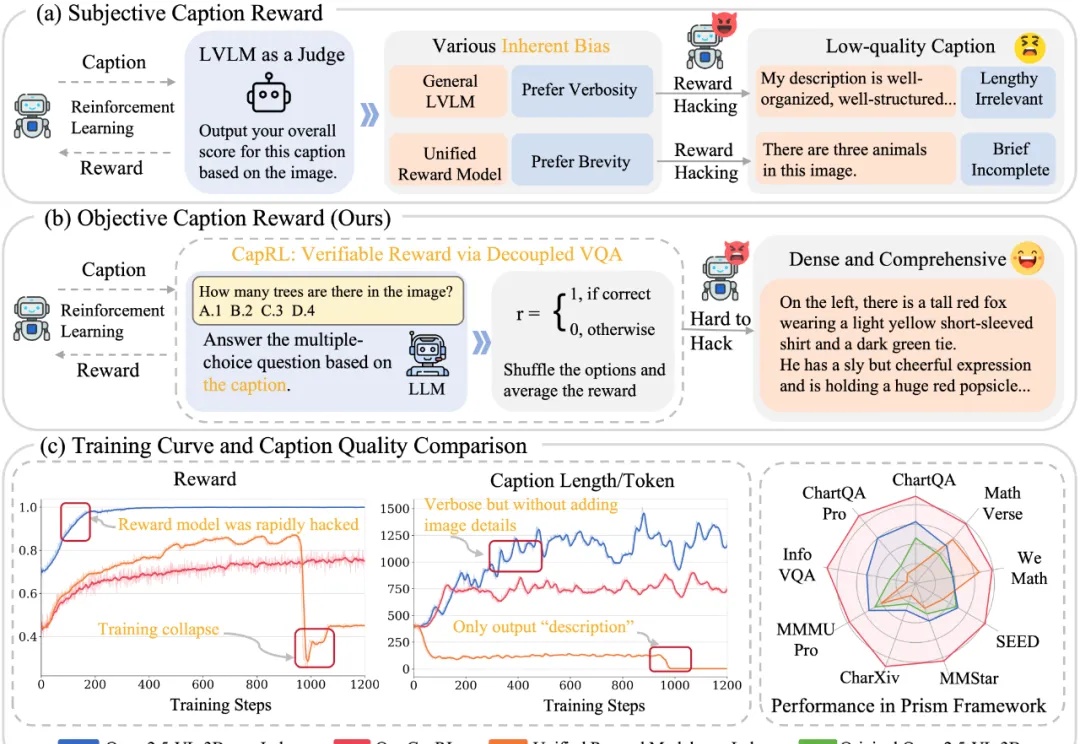
今天推荐一个 Dense Image Captioning 的最新技术 —— CapRL (Captioning Reinforcement Learning)。CapRL 首次成功将 DeepSeek-R1 的强化学习方法应用到 image captioning 这种开放视觉任务,创新的以实用性重新定义 image captioning 的 reward。

年初的 DeepSeek-R1,带来了大模型强化学习(RL)的火爆。无论是数学推理、工具调用,还是多智能体协作,GRPO(Group Relative Policy Optimization)都成了最常见的 RL 算法。

刚刚,DeepSeek 推出了全新的视觉文本压缩模型 DeepSeek-OCR。 该模型最大的突破在于极高的压缩效率: 20 个节点每天可处理 3300 万页数据,硬件要求仅为 A100-40G。
昨天,深度求索刚刚开源 DeepSeek-V3.2-Exp。今天,另一国产大模型之光智谱 AI 也正式发布了旗下新一代旗舰模型 GLM-4.6,刚好撞车 Claude Sonnet 4.5。但有一点不同,智谱的 GLM-4.6 会继续开源,它即将上线 Hugging Face、ModelScope 等平台,遵循 MIT 协议。